 accesses since April 8, 1996
accesses since April 8, 1996  copyright notice
accesses since April 8, 1996
copyright notice
accesses since April 8, 1996 However, the days of the Web are numbered. The technology behind the Web is outdated already and may not survive the decade. The current growth rate, which some estimate at 15% per month, suggests that if the end of the Web is to come soon, it will likely be cataclysmal. If this seems unrealistic, consider that this fate befell Gopherspace. As Figure 1 shows, Gopher lead the Web in packet volume as late as March, 1994. In the following twelve months Gopher presence on the Internet all but disappeared. Life cycles are accelerated to frightening paces on the Internet.
Technically, the Web is what is known as a resource level protocol. This protocol actually consists of two sub-protocols. The first, HyperText Transfer Protocol (HTTP), provides uniform handshaking and format conventions for client/server communication. The client computer establishes a connection with the server computer over the Internet by making a request, accepting a response, closing the connection, and taking some specified action.
The second sub-protocol, HyperText Markup Language (HTML), defines the internal structure of the Web's "documents". It accomplishes this through a primitive tagging convention which identifies contained or referenced resources. For example, a sensitive (clickable) document anchor which points to a uniform resource locator (URL) would be couched within the tag pairs "<A HREF = ....>" and "</A>"; an image would be identified by the tag"<IMG SRC=....>", and so forth. While unsophisticated, it works - at least for the most part. The HTML information which corresponds to an Web resource is called its "source".
These two protocols provide an Internet network information retrieval (NIR) environment. The Web is one such environment. Gopher is another. Wide Area Information Service (WAIS) is a third. Hyper-G [5] is a fourth, and Java [6] is a fifth. Each of these environments have their own respective cast of clients which support the information exchange. For example, the most popular navigator/browser client for Gopherspace is Gopher while the most popular search engine is Veronica. For the Web, that distinction would go to Netscape and perhaps Lycos. For Hyper-G, the leading client is Harmony, while Hot Java is the leading (and only, at the moment) Java client.
The point is simply that network information retrieval environments are really just information resources and popular client-server tools which operate under well-defined protocols for the sharing of information.
Another view which sheds more light on potential impact is one which emphasizes the difference between these alternatives and the Web itself. We'll pursue this line.
Consider Java (the language) and Hot Java (the client). The departure from existing Web clients may be thought of in terms of the primacy of the procedural over the static. The Web was first and foremost a mechanism to present static media over the Internet. Text came first, followed quickly by graphics in various formats, tables, interactive forms, and so forth. But in each case, the focus remained on what the animators call the still frame - moving images and sound were very much afterthoughts in the scheme of things. And so were the methods by means of which they would be presented.
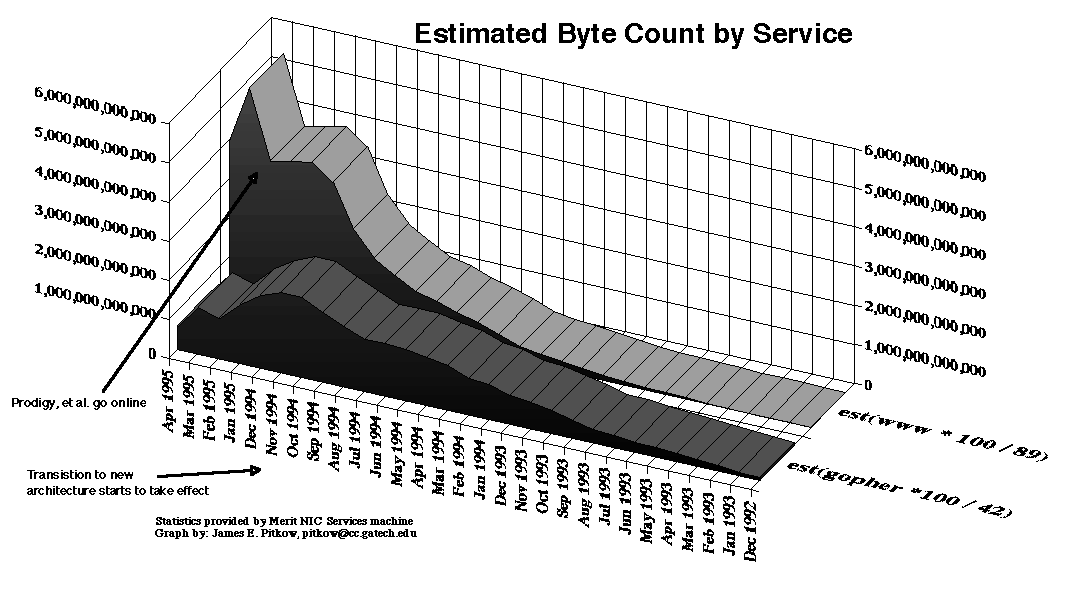 Figure 1. Estimated byte count by service
Figure 1. Estimated byte count by service
The philosophy behind Java may be though of in terms of the primacy of procedure over data. If one views the fundamental, packet-based exchange of information between client and server as a process (rather than an entity) one looks for different characteristics in both the client and the server. So Java begat the image of packets as data-cum-peruser, rather than packets as data alone.
We may think of Hot_Java-space as millions of personalized helper apps bundled with the data that drive them. On this account, one no longer thinks of something static like an HTML document, one thinks of an activity or process which will be launched by accessing a URL - the digital distribution of executables with, by and for the data. There are, of course, other issues which are germane - security and distributed computing among them - but this overview is enough for present purposes.
Next, consider Hyper-G. The departure from existing Web clients is in terms of indexing and search mechanisms and in the way that the data is distributed.
Once again, there is a clear difference in the underlying model. The Web is fundamentally egocentric. That is, from any user's perspective, the Web appears as a collection of resources locatable through a single link, or a link of that link, and so on. A Web "database" is thus a stratified or flat collection with no superimposed structure.
With Hyper-G, the database has structure. Resources are not a collection of separately addressable documents, but separately addressable collections of documents. This difference has significant consequences in the behavior of the client. The resources themselves are liberated from the restrictions of a flat cyberspace.
In implementation, Hyper-G cuts to the quick of cyberspace navigation. On the Web account, navigation is accomplished through unidirectional links (with backup). To define the independent collections of information, Hyper-G assumes that the linkages are bi-directional. One collection links to other collections, which also link to it. It is in this way that the collections take on a utility which is independent of the individual accesses to them.
It is easy to see the advantage of Hyper-G databases when one looks to the way organizations are administered. Projects link to departments which link to divisions, etc. But this organization ignores the information exchange which is independent of the governance structure of the organization. So if one individual contributes to the aggregate knowledge base of the organization with someone outside of the normal reporting relationships, reflecting that information will be ad hoc. On the Hyper-G account, the bidirectional links simply transcend the traditional structure.
Is Hyper-G a radical new approach to cyberspace? Is it a displacing technology?
It may be instructive at this point to consider those factors which contributed to the success or failure of current Web technologies. Since cyberspace is a collection of digital resources which interconnect computer systems (for the moment, primarily client-server systems) operating under a common set of protocols, it may be useful to see just how ephemeral the underlying protocols are to the long-term success of the Web product. That investigation may help us identify those success factors which have and will continue to distinguish the enduring client-server systems and resources from the transient.
Toward that end, we list what we consider to be important keystones to client-side product success and then relate these to actual experiences in Web client product development. Some of these ideas derive from our earlier work [2].
1. Locate the appropriate technological horizon. By this we mean the sensitivity to the entire technology "front" as opposed to individual data points. This requires placing the technology of interest in the context of alternative technologies as they move through time. We observe here that this is a technological and not a managerial ability.
Examples: X Mosaic. By late 1992, Marc Andreesen and his colleagues at the National Center for Supercomputing Applications (NCSA) at the University of Illinois had developed just the right perspective on Web technology. Andreesen could see much of the horizon and that gave his Web navigator/browser client, X Mosaic, the competitive advantage. It is too often forgotten that Mosaic was actually the second browser released for X Windows. The first was Viola, which is now of only historical interest. Both were "freely available" software, and yet only one survived beyond the Web's first year.
The reason for X Mosaic's success was that as a technology it addressed the need along the entire technological front. It satisfied the multimedia demands of users with respect to the then-available multimedia resources on the Web. It had a look and feel that was predictable from the X Windows interface then in use by the early Web users, and it maintained its currency despite the chaotic first year of the Web. These characteristics were essential to the success of early Web clients. Client browsers which were contemporaries of X Mosaic - Samba for the Macintosh and Cello for Windows - are non_entities at this point precisely because their developers failed to reflect such insight.
2. Avoid Technological Surprises. This was reported to be one of Thomas J. Watson's primary objectives for the IBM research groups. The objective is to view related technology through a "window" that would be large enough to anticipate those future advances early enough to adapt. Ironically, the failure to observe this guideline is the reason why IBM has essentially no Web presence at the moment.
From the client side, IBM's offering is Web Explorer for OS/2 - a classic case of too little, too late. Web Explorer would have made a fine browser as late as the fourth quarter of 1993 [3]. Unfortunately, it didn't ship until the fourth quarter of 1994, and by that time Web technology had passed it by. IBM had been caught off guard by working within an overly narrow "predictive window".
In the Web world, as with much of Internet technology, an entire product life cycle may be 18 months or less. If a brand name lasts two years it may well be attached to a different company or organization at the end than in the beginning. With this sort of volatility, there just isn't much room for strategic errors in product development. One technological surprise may mean the end of the product.
3. Maintain Technological Perspective. The inability to maintain technological perspective contributes as much as anything else to product mortality on the Web. The reason is that the competitive pressures and rapid deployment of the technology makes the market very unforgiving of mistakes. There seem to be at least three main causes for the absence of perspective.
Technological ambivalence encourages missed opportunities and mis-management of resources. An example of this may be found in Microsoft's and IBM's delayed entries into the Web client market. Uncertain of the future of multimedia Internet services, they waited until the standards and protocols became informally codified and diffused, thereby ensuring that neither organization would exert much influence. While this may be reversible for Microsoft because of overpowering dominance of the desktop applications and operating systems arenas, it is too late for IBM. Ambivalence did it in.
Second, there is technological myopia. Such was the case with micro-channel architecture and the Lisa when the project managers became so fixated on their own environment that they (mistakenly) imposed it onto the unreceptive consumer. In the Web world there are myriad examples. Win Gopher comes immediately to mind. A splendid product from a programming point of view, its major deficiency was that it provided a solution to a problem that didn't really exist. Win Gopher provided cybermedia support for the Gopher environment in much the same way as Web browsers. The problem is that Gopherspace lacks cybermedia. Predictably, the public chose to avoid a product which enabled them to view the non-existent.
The history of OS/2's Web Explorer also illustrates this deficiency. A quick review of the features reveals that it trailed in every category of major innovation for 1994 [3]. It lacked multi-threading, multi-windowing, integrated search capability, dynamic linking, sophisticated hotlist and bookmark management, to name but a few key features of state-of-the-art Web client browsers
Third, there is herd mentality - the desire to go the way of other successful developers. Regrettably, this is an all-too- common problem in U.S. business because of the absence of technical skills in the upper echelons of management. In the absence of a good idea, we decide to do what others have done before us.
The paralyzing effect of this phenomenon is best illustrated in the digital products arena. The reason for this is twofold. First, changes in digital technology take place so quickly that the bad decisions are felt almost immediately. Second, there is virtually no customer loyalty in digital technology. A few months from product announcement, the best new technology can be the market leader. This doesn't happen with soap, automobiles or even telephony.
An excellent illustration of this is the development work that continued with the Unix X clients after mid-1993. At that time Unix clients had over 90% of the market [1]. Those who couldn't interpret that statistic correctly continued to develop clients in what is now a near-insignificant percentage of the user community. By April, 1995 Unix clients represented about 8% of Web activity. Smart money foresaw this and abandoned the Unix ship by late 1993 [1]. By 1995 it was already sinking.
4. Finally, the most important success factor of all: focussing on paradigms and not trends. Trends tell us what was interesting. Paradigms tell us what will be interesting. Following technology trends are like following the proverbial yo- yo as the player is walking up and down stairs - it is difficult to infer the overall pattern from the behavior of the yo-yo.
While there isn't space to go into detail, I will conclude with two examples. One paradigm which will stand the test of time is the desktop metaphor, which includes special cases like cut-copy- paste, drag-and-drop, and so forth. One now digitally cuts, copies and pastes audio files and movies just as one did with ASCII text just a decade ago. This is to be contrasted with such ephemeral phenomena as object-oriented GUI's. Whether one views front-plane or interface elements as objects with inheritability and class associations is really external to how the user uses them. Were one to look to the future of Web clients in terms of internal code structure rather than user behavior, one would likely have a distorted overview.
Another paradigm worthy of mention is non-linear document traversal [4] as such. In this case, the corresponding trend would be hypertext. What is enduring about the former but not the latter is that it is a more robust concept. The important notion for future Web clients will be the ability of using media of all forms independently of the structure of its creation. However, hypermedia only goes half-way: the structure of the links is still prescribed by the information provider. In the end, this will have to be relaxed in order to accommodate the future information needs of Web users.
While we illustrate our observations with reference to the client-side navigator/browsers for the Web, our remarks apply to the commercializing of Internet client-side technology and resources generally.
The Web and its traditional clients, Hyper-G and Java are but weights on the lever of cybermedia exchange. Where are the real innovations? It's hard to say.
All three environments, in their own distinctive ways, view cyberspace as different sorts of entities. With Java, the process is the message. With Hyper-G it's the anti-egocentricity that is important. Both have different views of cyberspace than the Web, and both views are exceedingly difficult to emulate within the framework of existing Web technology.
It is clear that the advantages of Java and Hyper-G are real and not imagined, and that these advantages, and many more which will materialize in the new and strange-sounding, client-server protocols in the near future, will render the classical Web as we know it obsolete. The Web in this sense has little future. It will continue to grow by leaps and bounds until it is totally and quickly displaced by superior technologies. Other protocols will do to it what it did to Gopher.
Java and Hyper-G are necessary, but not sufficient, preconditions to the demise of Webdom. They illustrate weaknesses in the original Web model, but are not in themselves capable of doing it in. For that to happen, we need a new "killer" protocol/client pair which is so overpowering in itself that it will detract attention from its predecessors. Java and Hyper-G aren't adequate to the challenge.
One must remember that all client-side evolution is basically absorptive. That is, the newest clients absorb the technology of the predecessor and advance the envelope incrementally. Indeed, Java and Hyper-G are intended to be superset-technologies: they will support Web HTML and HTTP protocols as well as their own. But what makes a technology snap is the development of technologies where their own proprietary advantage is actually more important than the technology which they absorb. This is what did Gopher in. What the Web offered beyond Gopherspace was more important than Gopherspace itself.
So we're looking for a technology which will, in effect, out Web the Web. The section above provides guidelines on what indicators are relevant in identifying these technologies when we see them. Those success factors will be present in the superseding technology, just like they were with the successful Web clients.
What do we know for sure? For one, the next generation of successful client-side technologies will be a "grand unifier" of cybermedia under some set of resource-level protocols. It is the evolution of these protocols which will dictate what can and what cannot be accomplished and in what features and strengths product competitiveness may lie. The client's will follow along in due course.
[1] Berghel, H., "The Client Side of the Web," Communications of the ACM, January, 1996 [forthcoming].
[2] Berghel, H.: "Strategies for Success in Developing and Marketing Web Software," Proceedings of the 1995 Decision Sciences Institute Conference, Decision Sciences Institute Press (1995) [forthcoming].
[3] Berghel, H. OS/2, UNIX, Windows and the Mosaic Wars. OS/2 Magazine, May, 1995, pp. 27-35.
[4] Berleant, D. and H. Berghel, "Customization Information", Part I - IEEE Computer, 27:9, pp. 96-98 (1994); Part II - IEEE Computer, 27:10, pp. 76-78 (1994).
[5] Fenn, B. and H. Maurer, "Harmony on an Expanding Net," interactions, 1:4, pp. 29-38 (1994).
[6] The Hot Java Browser: A White Paper, Sun Microsystems, http://java.sun.com/about.html.